SenseVoice本地部署教程
SenseVoice本地部署
准备
用conda创建一个虚拟环境,方便隔离,python版本建议3.11、3.10
1 | # 不许说你没下anaconda |
拉取SenseVoice代码
进入一个合适的文件夹,再文件夹里进入cmd执行
1 | # 不许说你没有git |
进入我们拉取来的文件,可以看到文件里有一个名为requirements.txt的文件,内容如下,这些是我们需要下载的包
1 | torch<=2.3 |
我们在此文件夹执行
1 | (SenseVoiceTest) D:\code\Test\SenseVoice>pip install -r requirements.txt |
这样就会开始下载需要补充的包
运行代码
使用IDE执行或者使用python命令
1 | python -u D:\code\Test\SenseVoice\webui.py |
记得改环境
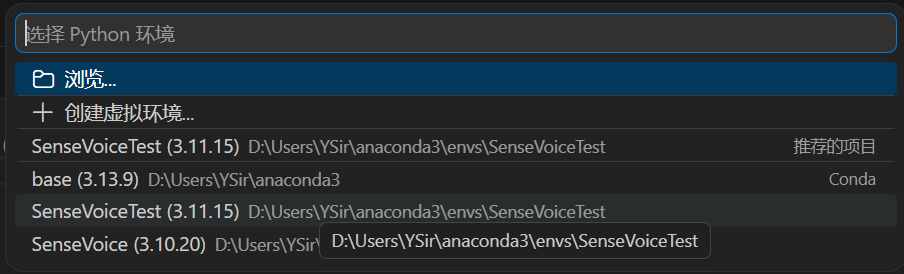
在执行webui.py后如果没下模型会自动补全需要的模型
进入 http://127.0.0.1:7860 即可开始使用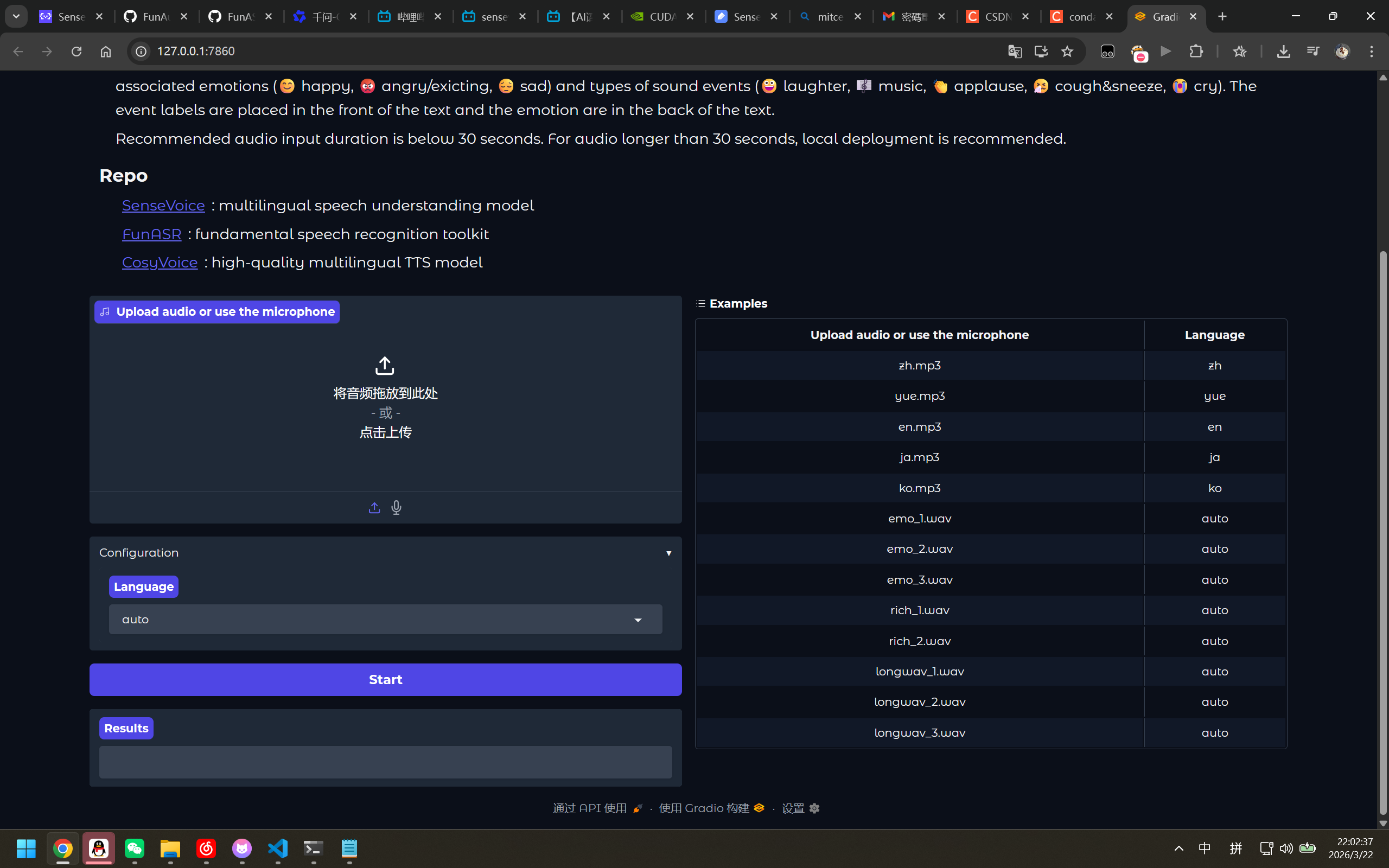
此时只能上传.wav文件,如果想支持其他音频文件.mp3,我们需要下载FFMPEG
选择full标识的进行下载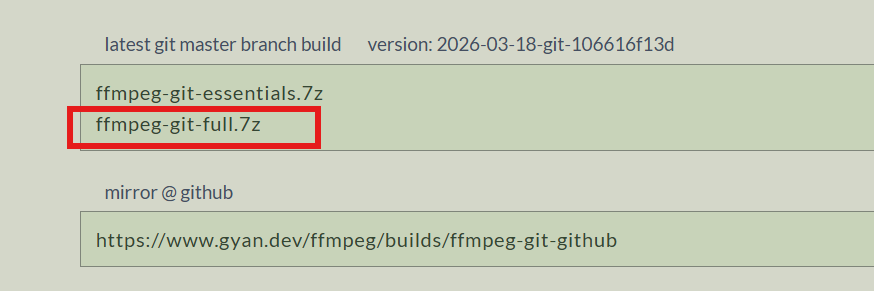
下载完后找到一个合适的地方解压,进入其中bin文件夹,复制路径,添加到系统环境变量path
1 | D:\Tool\ffmpeg-2026-03-18-git-106616f13d-full_build\bin |
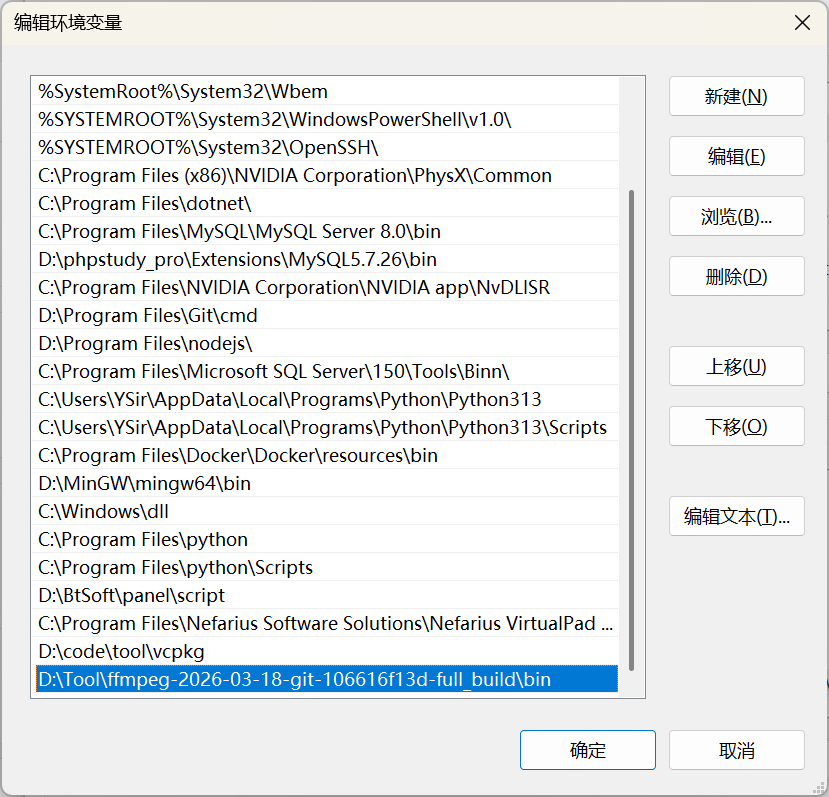
现在我们可以使用.wav以外的其他音频识别语音和情绪了
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 YSir_Blog!